再过一个星期,老牌安全学术会议 RAID 的2023年度会议就要在香港召开了,本周 ACM 数字图书馆已经公布了会议所有录用论文列表,但是 PDF 似乎还要等到下个星期才会提供免费访问。先要先睹为快,就跟随我们来看看那些已经公开的论文吧~

今天要推荐的论文是一篇关注搜索引擎安全的研究论文 Boosting Big Brother: Attacking Search Engines with Encodings

阅读这篇论文,首先需要我们的读者具备一定的文学功底,否则无法理解 Intro 中的这一段论述:

读完这段话后回到论文,作者把研究聚焦于搜索引擎——既包括了商业的 Google 和 Bing,也包括了开源的 Elasticsearch——是否会在处理特定编码方式(encoding)的文本时遭受攻击。这种攻击究竟是何种类型的攻击,我们先从安全威胁模型说起。首先,大家默认搜索引擎是一个“权威知识库”,当你向它提问时,可以认为它返回的结果确实是网络上具有代表性的结果(当然我们都知道 Bing 在搜索技术问题时返回的那些 CSDN 链接并不满足这一条件)。但是你看看下面这两个看起来完全一样的输入查询(都是“dog”),却返回了完全不一样的结果,这是为什么?

答案和文本编码息息相关:这里面涉及一种很经典的攻击技术——Homoglyph Attack!所谓 Homoglyph Attack 是一种视觉欺骗攻击方式,通常是利用字符集中长得很像的字符来互相冒充。上图的例子中,就是利用了两个Unicode字符(U+501 & U+3BF)来冒充“dog”

Homoglyph Attack 这种攻击方式,大家最熟悉的也许是针对 URL 的 Punycode 钓鱼攻击吧?近些年来,研究人员也提出了很多类似的攻击,例如将恶意字符注入到程序的文本代码中,插入一些人肉 code review 无法察觉的后门。慢雾科技有一篇科普文章《Unicode 视觉欺骗攻击深度解析》推荐大家去阅读:
https://web3caff.com/zh/archives/32713
不过本文作者并没有局限在 Homoglyph Attack 这一招上,早在 2022 年的 IEEE S&P 会议上,他们就已经在论文 Bad Characters: Imperceptible NLP Attacks 中讨论了多种视觉欺骗方法,包括不可见字符、阅读顺序颠倒(阿拉伯语?)等。在本文中,作者准备了一个用来攻击的“Bad Search Wiki”(如下图所示),用来“污染”搜索引擎(这个 wiki 在网上挂了一年整,并且在其他地方提供了很多链接让搜索引擎来检索到这上面的内容)。此外,为了测试 Elasticsearch,作者下载了一个简化版的 Wikipedia 然后对其中的文本也做了处理,然后让 Elasticsearch 来检索这个版本(imperceptibly perturbed version)的 Wikipedia。

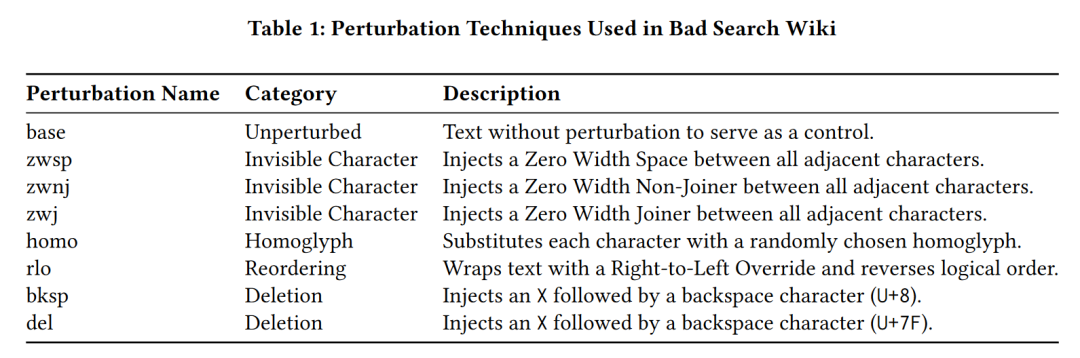
具体地,在 Bad Search Wiki 中,作者运用了此前IEEE S&P 会议论文中提到的多项技术(如下表所示)对文本进行变换。针对本地搜索的测试也采取了类似的处理。
针对搜索引擎的结果(Search Engine Results Page,SERP),作者分析了两种指标:第一种指标 hiding 指的是在正常的查询(benign query)的情况下,搜索结果是否包含处理后的网页;第二种指标 surfacing 指的是当输入了恶意查询(perturbed query)时,搜索结果是否包含处理后的网页。针对 Google、Bing 和 Elasticsearch 的测试结果如下所示:
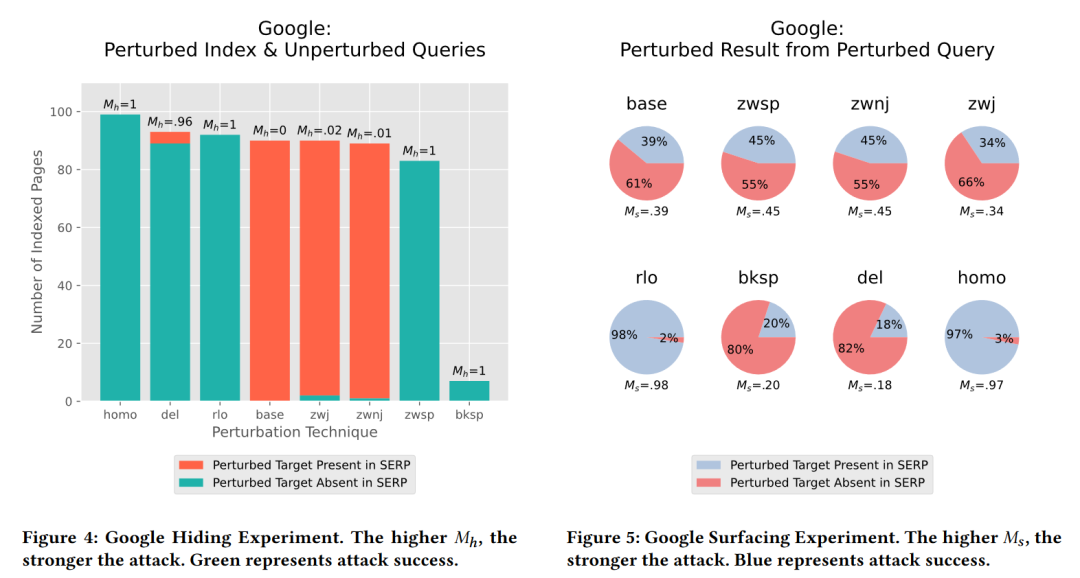
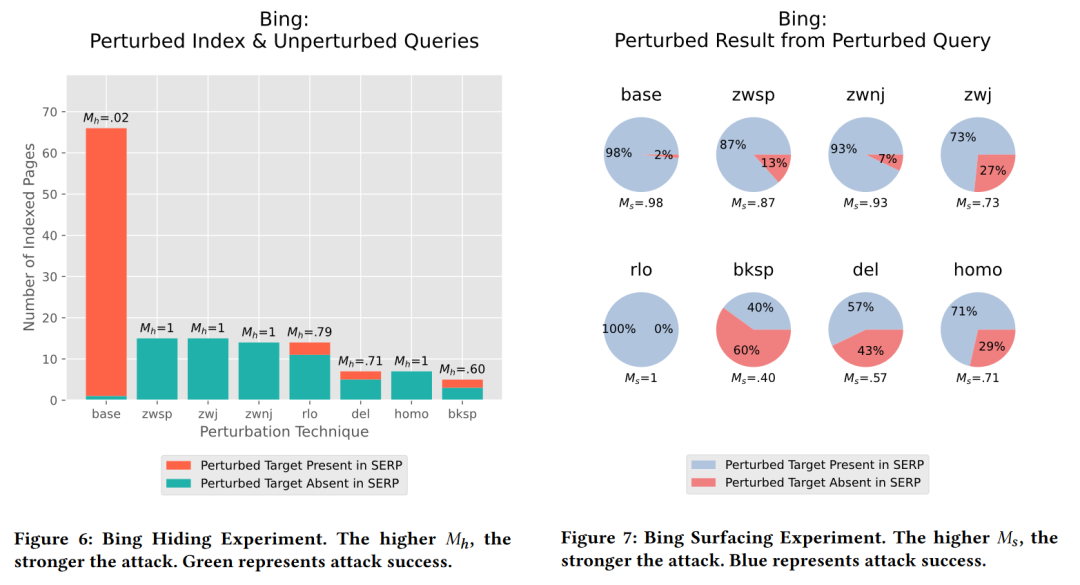

仔细看结果就会发现,并不是所有的文本变换方式都能欺骗和污染搜索引擎,测试显示只有某些特定的变换(例如 rlo 也就是变换阅读顺序)效果会特别好。而且不同的搜索引擎因为在文本处理过程中使用的 NLP 技术可能有所差异,对不同变换攻击的免疫效果也不同。
作者还顺手测试了一些基于大语言模型的 Chatbot 然后发现攻击同样有效果:

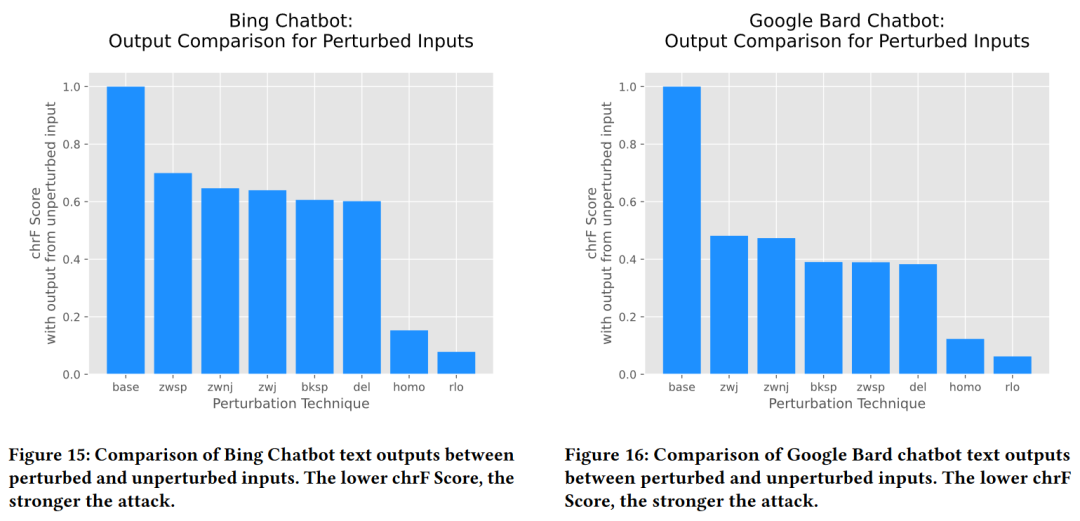
总结一下,目前搜索引擎(其实也包括各种各样的文本检索和处理工具)在面对文本变换时,由于它们和人类的“阅读理解”方式的巨大差别,往往会在分析和最后呈现结果时,被一些特定构造的有害输入影响。当然这种攻击仅限于人类阅读者,未来也许我们都被 Matrix 接管了(泡在养料罐子里面,脑子插管),这种攻击也就不复存在了。

论文:https://arxiv.org/pdf/2304.14031.pdf
实验数据:https://github.com/nickboucher/search-engine-attacks